AURA
Offline AI developer assistant with voice commands and system automation.
Overview
Problem
Enterprise developers often rely on cloud-based AI assistants that require continuous internet connectivity, introduce data privacy concerns for proprietary codebases, and incur recurring subscription or API costs. Organizations need an AI assistant that operates entirely on local infrastructure while maintaining full ownership of their data and workflows.
Solution
Designed and developed AURA (Autonomous Unified Response Architecture), a fully offline AI assistant that runs entirely on local hardware. AURA combines local LLM inference through Ollama, voice interaction, persistent memory, codebase-aware retrieval, and a modular plugin ecosystem to provide secure, private, and extensible AI-powered automation for developers
Tech Stack
Architecture
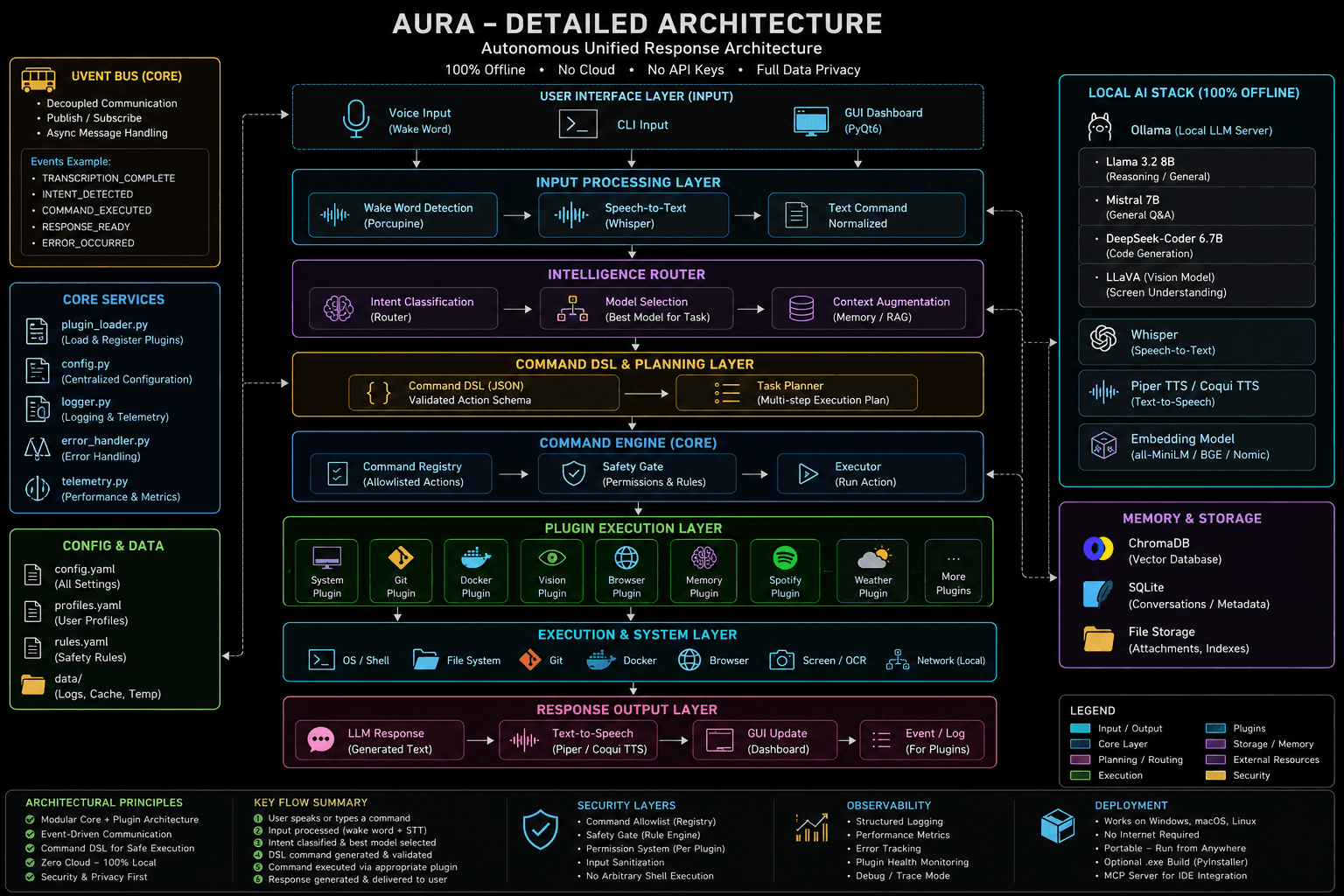
Features
- Fully offline AI assistant powered by local LLMs through Ollama.
- Wake-word activated voice interface with local speech-to-text and text-to-speech.
- Codebase-aware contextual understanding using ChromaDB vector search and RAG.
- Modular plugin architecture enabling extensible capabilities without modifying the core system.
- Intelligent routing layer that selects optimal models based on task complexity and intent.
- Developer automation for Git, Docker, file management, and system operations.
- Persistent long-term memory with semantic retrieval across sessions.
- Desktop dashboard for monitoring commands, system status, and AI activity.
- MCP-compatible architecture for IDE and external tool integrations.
Technical Decisions
Adopted Ollama for local LLM serving to ensure complete offline functionality and model flexibility
Implemented a plugin-based architecture to isolate features and improve maintainability, scalability, and community extensibility
Chose ChromaDB for persistent vector storage and fast semantic retrieval on local hardware
Used Whisper and Piper TTS to achieve a fully offline voice interaction pipeline
Selected PyQt6 for a lightweight, Python-native desktop interface with lower resource consumption than Electron-based alternatives
Introduced a Command DSL and Intelligence Router to safely map AI-generated intents into validated system actions
Challenges
- Optimizing local LLM performance and response latency on consumer-grade hardware.
- Building a reliable wake-word, speech recognition, and command execution pipeline.
- Designing a secure execution framework that prevents unintended AI actions.
- Managing efficient vector index updates as project files and context evolve.
- Ensuring seamless operation across online and air-gapped environments.
Outcomes
- Built a privacy-first AI assistant with zero cloud dependency and 100% local execution.
- Achieved support for voice commands, contextual memory, developer tooling, and desktop automation.
- Designed a scalable plugin ecosystem for future integrations and community extensions.
- Developed an MCP-compatible architecture for IDE and external tool interoperability.
- Enabled deployment in secure and air-gapped environments where cloud AI solutions are unsuitable.